- Published on
Behind the scenes of a RAG based LLM powered QAChatBot - LangChain - GPT4
- Authors
- Name
- Mohit Appari
- @moh1tt


In this article we're gonna look at how RAG based LLM powered QA Chatbots work, and how LangChain uses RAG to build a Q&A Chatbot. Thanks to Alex Litvinov for such informative article on Building ZoomcampQABot
Let's start with getting a better understanding of what a RAG is.
We know in the recent years how Large language models have undergone a remarkable boom, fundamentally reshaping the landscape of natural language processing (NLP) and artificial intelligence. These models, such as OpenAI's GPT series and Google's BERT, are characterized by their vast size, often comprising billions or even trillions of parameters. What sets LLMs apart is their ability to understand and generate human-like text at an unprecedented scale and complexity.
So, what if we have custom data that we want our language model to be trained on. This can be accomplished by using a RAG model.
Retrieval augmented generation (RAG)
or RAG, is an architectural approach that can improve the efficacy of large language model (LLM) applications by leveraging custom data. This is done by retrieving data/documents relevant to a question or task and providing them as context for the LLM. RAG has shown success in support chatbots and Q&A systems that need to maintain up-to-date information or access domain-specific knowledge.
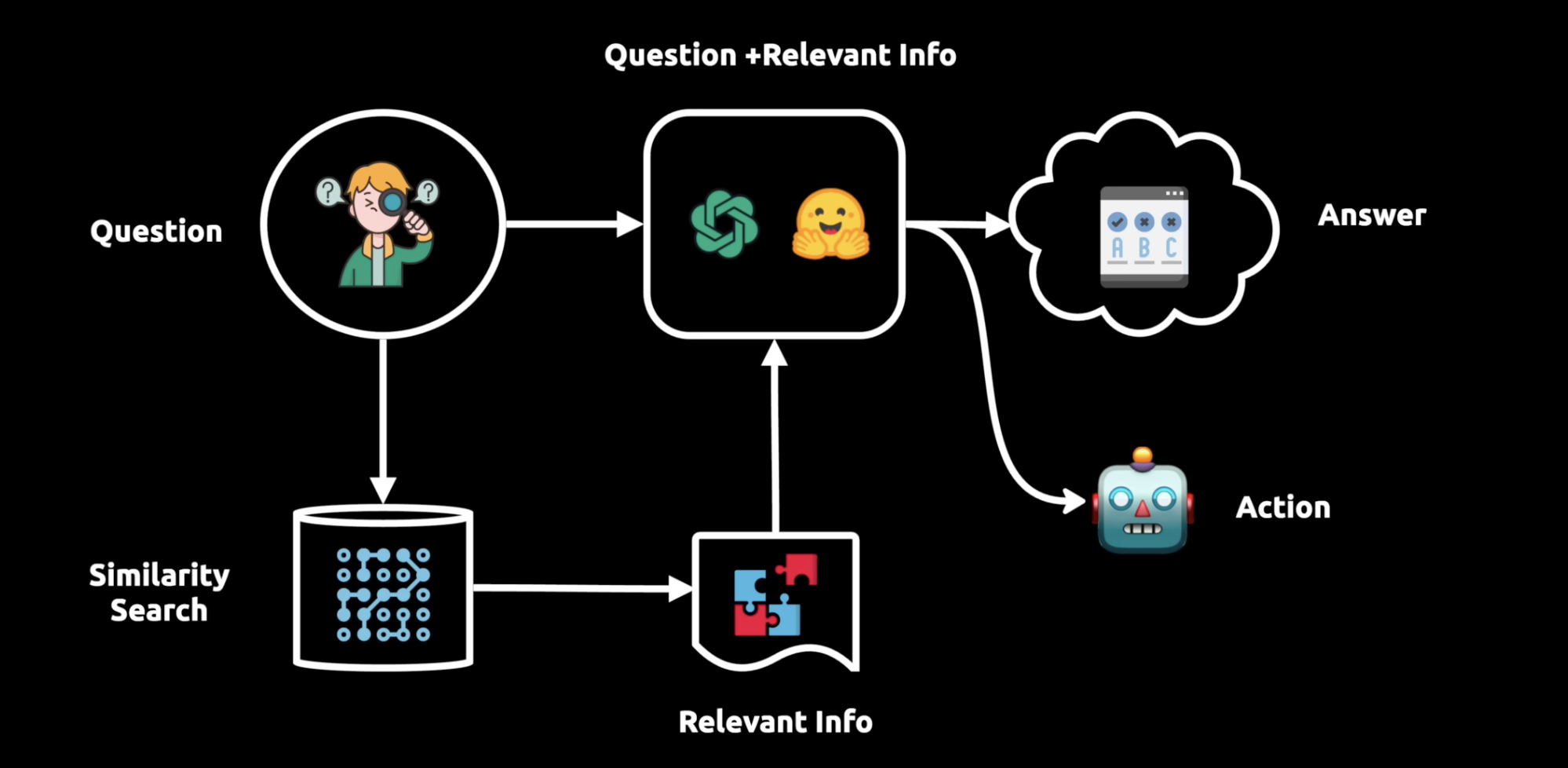
It basically consists of three main components:
- Ingestion
Done offline, where the data is ingested and indexed, Before we get the question from user. We collect the data from the data source, break it to smaller chunks and then embbbed it to a vector database. This allows us to runsemantic search(takes meaning into account). - Retrieval
Get the query from the user, and then run a semantic search on thevector databaseto get the most relevant documents. - Generation
Consturct the final prompt by combining the query and the retrieved documents, and then pass it to theLLMto get the answer.
RAG can be seen as prompt engineering.

Now that we know how RAG works, let's look into what LangChain is and how it uses RAG to build a Q&A Chatbot.
What is LangChain?
Langchain allows you to connect a LLM like GPT4 to your own source of data. Like referencing an entire database of your data. LangChain helps us build a pipeline shown in the image above, that helps us to provide answers to our questions, as well as take actions based on the answers.
- It offers various modules such as model interaction, data connection and retrieval, chains, and agents to enable the development of effective NLP apps.
- LangChain can be used for various applications like customer service chatbots, coding assistants, healthcare diagnostics, marketing and e-commerce tools, and more.
- In simple terms, LangChain serves as a valuable framework for developers working with AI and NLP applications, offering a range of features to streamline the development process and create sophisticated language model-driven applications across various industries.
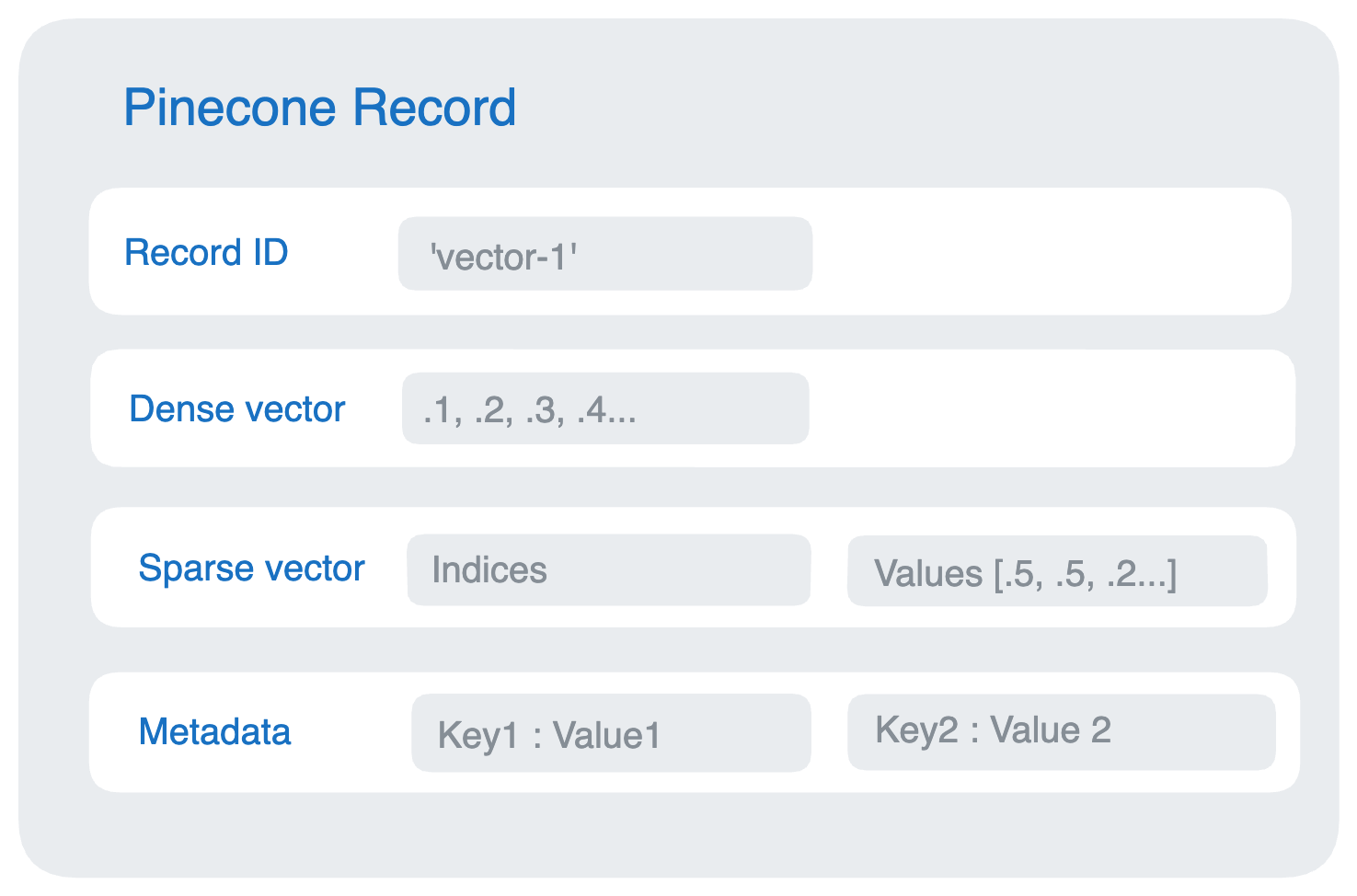
Why use a Vector Database?
To feed data to our model as context along with our query, we need to have a way to retrieve the most relevant documents. This is where the vector database comes in. It allows us to run semantic search on the data and retrieve the most relevant documents. This is done by converting the data to vectors and then indexing them in the database.
Vector databases are essential for Retrieval-Augmented Generation (RAG) applications as they efficiently store, manage, and index high-dimensional vector data, enhancing the efficiency and accuracy of RAG systems. These databases play a crucial role in storing and querying high-dimensional data for AI and machine learning applications, providing swift and low-latency queries, especially for similarity searches in RAG use cases. Vector databases offer features like efficient storage and retrieval, scalability, query performance optimization, dimensional flexibility, integration with AI frameworks, and security control.
One of the open source Vector database is Pinecone with good documentation and integration with LangChain.
What's next ?
Well, with that knowledge, you are now ready to build your own Q&A Chatbot using LangChain and RAG. If you'd like to follow along on how I created my own RAG based LLM for my coursework, you can check my blog here
Happy Learning! 🚀