- Published on
Data Engineering Zoomcamp - Unveiling NYTaxi Data and Essential Data Engineering Tools
- Authors
- Name
- Mohit Appari
- @moh1tt


In this article we're gonna go through all the weeks of the Data Engineering Zoomcamp and setup the required tools to run week 4 and onwards on our machine.
Note: This article is incomplete and doesn't contain the entire walkthrough and would be completed soon, before the datacamp ends. Cheers!
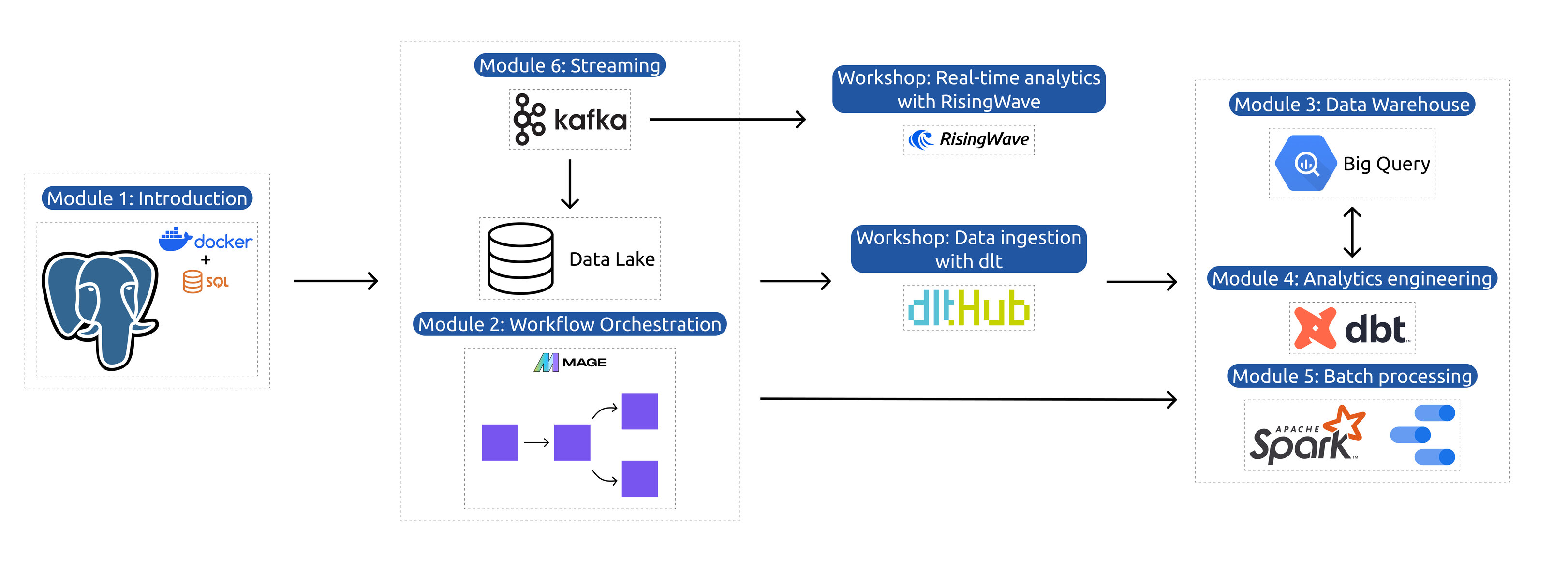
- Week 1: Docker-Terraform-PostgreSQL - Setup terraform - Week 2: Workflow Orchestration using Mage - Setup mage - Using dlthub for efficient data loading
- Cons of using dlt, Mage (Problems Faced) - How to load large data ? - Week3: Data Warehousing using BigQuery, Storage - Week 4: Analytical Engineering-DBT - Week 5: Batch Processing using Apache Spark
Week 1
- We look into
docker,docker-compose,networks,volumes,images,containers,ports,env variables,dockerfile,docker-compose.ymlanddocker-compose.override.ymlfiles. - We also went through basic
SQLcommands andPostgreSQLdatabase. - Setting up infrastucture for the project on
GCPusingTerraform.
We're gonna set up our infrastucture required for the project now, using Terraform. We would require, - Cloud Storage - Big Query for now.
Terraform
To set up terraform, we're gonna use terraform on docker image, using this documentation
To begin with, we need to install terraform on our machine. We can do that by running the following command,
# For Mac, First, install the HashiCorp tap, a repository of all our Homebrew packages.
brew tap hashicorp/tap
brew install hashicorp/tap/terraform
# To update to the latest version of Terraform, first update Homebrew.
brew update
brew upgrade hashicorp/tap/terraform
# To verify the installation, use the terraform command with no additional arguments.
terraform --help
If you encounter an error, like zsh: command not found: terraform, you can try to use the following command,
bash reinstall terraform
Now that we have terraform, let's create our GCP instances. Setup guide can be found here
Then we create a main.tf file and add the following code,
terraform {
required_providers {
google = {
source = "hashicorp/google"
version = "4.51.0"
}
}
}
provider "google" {
credentials = file("<NAME>.json")
project = "<PROJECT_ID>"
region = "us-central1"
zone = "us-central1-c"
}
# Since we're using storage
resource "google_storage_bucket" "ny_taxi_mohit" {
name = "ny_taxi_mohit"
location = "US"
}
And after following the documentation above and running init, plan and apply commands, we should have our GCP instances ready.
There you go, We have our infrastructure ready for the project. Now we can move on to the next weeks.
Week 2
We are gonna look into workflow orchestration using mage. We're gonna use mage to automate our tasks and run them in a sequence.
Mage
To setup Mage, which is a workflow orchestration modern data engineering tool, we follow the documentation here The official documentation recommends we download mage using docker-compose, so that's what we're gonna do.
git clone https://github.com/mage-ai/compose-quickstart.git mage-quickstart \
&& cd mage-quickstart \
&& cp dev.env .env && rm dev.env \
&& docker compose up
Once the server is running, open http://localhost:6789 in your browser and explore!
For the course we need
yellow_taxidata for 2019green_taxidata for 2019fhvdata for 2019
So we're gonna load the data from the url provided in parquet format.
The code block for data_loader in mage to ingest the data of yellow, green taxi of years 2019,2020 is,
import io
import pandas as pd
import requests
import pyarrow as pa
import pyarrow.parquet as pq
from mage_ai.settings.repo import get_repo_path
from mage_ai.io.config import ConfigFileLoader
from mage_ai.io.google_cloud_storage import GoogleCloudStorage
from pandas import DataFrame
from os import path
import itertools
if 'data_loader' not in globals():
from mage_ai.data_preparation.decorators import data_loader
if 'test' not in globals():
from mage_ai.data_preparation.decorators import test
@data_loader
def load_data(*args, **kwargs):
"""
Template code for loading data from any source.
Returns:
Anything (e.g. data frame, dictionary, array, int, str, etc.)
"""
services = ["yellow", "green"]
years = ["2019", "2020", "2022"]
months = list(i for i in range(1, 13))
config_path = path.join(get_repo_path(), "io_config.yaml")
config_profile = "default"
# change bucket name
bucket_name = "ny_taxi_mohit"
for service, year, month in itertools.product(services, years, months):
print(f"Now processing:\nService: {service}, Year: {year}, Month: {month}")
month = f"{month:02d}"
file_name = f"{service}_tripdata_{year}-{month}.parquet"
request_url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
object_key = f"{service}/{year}/{service}_tripdata_{year}_{month}.parquet"
print(f"request url: {request_url}")
try:
response = requests.get(request_url)
response.raise_for_status()
data = io.BytesIO(response.content)
df = pq.read_table(data).to_pandas()
print(f"Parquet loaded:\n{file_name}\nDataFrame shape:\n{df.shape}")
except requests.HTTPError as e:
print(f"HTPP Error: {e}")
GoogleCloudStorage.with_config(
ConfigFileLoader(
config_path,
config_profile
)
).export(
df,
bucket_name,
object_key
)
@test
def test_output(output, *args) -> None:
"""
Template code for testing the output of the block.
"""
assert output is not None, 'The output is undefined'
Also, be sure to add path to your json keys file in io.config.yaml file.
It is giving me errors for large uploads, so I'm gonna use the dlthub package to upload the data to the cloud.
Dlthub
Modern data loading tool for efficent data loading. In this workshop we go through dlt which makes us load data from various sources to numerious destinations with simple pipelines. It's a python library that makes data loading faster, efficient and easy.
While we can load data through dlt or mage, I had tried loading the entire data using dlt, mage.
using dlt to load the data could be something like,
Following the documentation here, dlt
The code to upload data from api to gcs could look like this using dlt,
import dlt
import itertools
import requests
import io
import pyarrow.parquet as pq
def load_taxi_data_service() -> None:
# services = ["yellow", "green"]
# years = ["2019", "2020", "2022"]
# months = list(i for i in range(1, 13))
services = ["yellow"]
years = ["2019"]
months = [1]
# configure the pipeline: provide the destination and dataset name to which the data should go
pipeline = dlt.pipeline(
pipeline_name="load_taxi_data",
destination='filesystem',
dataset_name="ny_taxi_data",
)
for service, year, month in itertools.product(services, years, months):
print(
f"Now processing:\nService: {service}, Year: {year}, Month: {month}")
month = f"{month:02d}"
file_name = f"{service}_tripdata_{year}-{month}.parquet"
request_url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
object_key = f"{service}/{year}/{service}_tripdata_{year}_{month}"
print(f"request url: {request_url}")
try:
response = requests.get(request_url)
response.raise_for_status()
data = io.BytesIO(response.content)
data = pq.read_table(data).to_pandas()
print(
f"Parquet loaded:\n{file_name}\nDataFrame shape:\n{data.shape}")
info = pipeline.run(data, table_name=object_key,
write_disposition="replace")
print(info)
except requests.HTTPError as e:
print(f"HTPP Error: {e}")
if __name__ == "__main__":
load_taxi_data_service()
with some changes in the secrets.toml file,
[destination.filesystem]
bucket_url = # replace with your bucket name
layout = "{table_name}"
[destination.filesystem.credentials]
project_id = # please set me up!
private_key = # please set me up!
client_email = # please set me up!
from gcp.json file.
Issues faced with dltHub and Mage,
While we just got started with dlt and mage, there were few issues that we're faced using the tools.
- Though
Magewas easy to use and setup, It couldn't handle large data and loops which consumed lot of memory and crashed when it went above limit. - On the other hand
dlt, seemed to handle data perfectly but it was a bit complex to use and the files couldn't be custom named to segeregate them into folders. But other than that it was a good tool to use and fast.

So, How do we load large data ?
There is a custom python code mentioned on dezoomcamp, that can be used to load large data to the cloud with partition.
import io
import os
import requests
import pandas as pd
import pyarrow.parquet as pq
from google.cloud import storage
# switch out the bucketname
BUCKET = os.environ.get("GCP_GCS_BUCKET", "dtc-data-lake-bucketname")
print(BUCKET)
def upload_to_gcs(bucket, object_name, local_file):
"""
Ref: https://cloud.google.com/storage/docs/uploading-objects#storage-upload-object-python
"""
# # WORKAROUND to prevent timeout for files > 6 MB on 800 kbps upload speed.
# # (Ref: https://github.com/googleapis/python-storage/issues/74)
storage.blob._MAX_MULTIPART_SIZE = 5 * 1024 * 1024 # 5 MB
storage.blob._DEFAULT_CHUNKSIZE = 5 * 1024 * 1024 # 5 MB
client = storage.Client()
bucket = client.bucket(bucket)
blob = bucket.blob(object_name)
blob.upload_from_filename(local_file)
def web_to_gcs(year, service):
for i in range(12):
# sets the month part of the file_name string
month = '0'+str(i+1)
month = month[-2:]
# csv file_name
file_name = f"{service}_tripdata_{year}-{month}.parquet"
# request url for week 3 homework
request_url = f'https://d37ci6vzurychx.cloudfront.net/trip-data/{service}_tripdata_{year}-{month}.parquet'
print(request_url)
#request_url = f"{init_url}{service}/{file_name}"
r = requests.get(request_url)
open(file_name, 'wb').write(r.content)
print(f"Local: {file_name}")
df = pq.read_table(file_name)
#df.to_parquet(file_name, engine='pyarrow')
print(f"Parquet: {file_name}")
# upload it to gcs
upload_to_gcs(BUCKET, f"{service}/{file_name}", file_name)
print(f"GCS: {service}/{file_name}")
# The following two datasets are used in the Week 3 Video Modules
web_to_gcs('2019', 'yellow')
web_to_gcs('2020', 'yellow')
# The following dataset is necessary to complete the Week 3 Homework Questions
web_to_gcs('2022', 'green')
The above code will help us load the required data from NY_taxi to gcs. Once we get the data required for the course homework, we move on to the next module.
Week 3
Week 3 is all about analytical engineering and data warehousing using BigQuery and Storage. We're gonna look into the basics of BigQuery and how to use it to store and query data.
- We're gonna look into the basics of BigQuery and how to use it to store and query data.
- Difference between OLAP and OLTP
- External tables in BigQuery
- Partioning and Clustering in BigQuery And different ways to query data faster and use less memory and resources.
Week 4
In Progress
Week 5
There are 2 ways to process data,
- Batch Processing
- Stream Processing
In week 5 of the course we go over Spark and python wrapper for spark, pyspark. We use spark for batch processing. We go through the anatomy of internals of spark, joins and groupbys, and how to use spark to process large data. And alse SQL with spark, To get started with the homework, you can follow the jupyter notebook provided below,
# Installing spark
!pip install pyspark
from pyspark.sql import types
import pandas as pd
df_pandas = pd.read_csv('/content/fhv_tripdata_2019-10.csv.gz', nrows=1000)
df_pandas.dtypes
spark.createDataFrame(df_pandas).schema
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.master("local[*]") \
.appName('test') \
.getOrCreate()
df = spark.read \
.option("header", "true") \
.schema(schema) \
.csv('/content/fhv_tripdata_2019-10.csv.gz')
df.show()
df = df.repartition(6)
df.write.parquet('fhv_tripdata/2019/10/')
df.registerTempTable('fhv_trip_data')
Load Zones lookup table in similar fashion.
SQL Queries for the homework,
spark.sql(
'''
SELECT
COUNT(1)
FROM
fhv_trip_data
WHERE
DATE(pickup_datetime) = '2019-10-15'
'''
).show()
spark.sql(
'''
SELECT
MAX((UNIX_TIMESTAMP(dropoff_datetime) - UNIX_TIMESTAMP(pickup_datetime)) / 3600) AS longest_trip_hours
FROM
fhv_trip_data
'''
).show()
spark.sql(
'''
SELECT
z.LocationID,
z.Borough,
z.Zone,
COUNT(*) AS TripCount
FROM
fhv_trip_data f
INNER JOIN
zone_lookup z
ON
f.PULocationID = z.LocationID
GROUP BY
z.LocationID,
z.Borough,
z.Zone
ORDER BY
TripCount ASC
LIMIT 1
'''
).show()